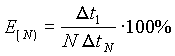In Proceedings of the Joint International Conference on Mathematical Methods and Supercomputing for Nuclear Applications, vol. 2, 1454-1466 (Saratoga Springs, New York October 5-9, 1997).
V. I. Arzhanov,
A. V. Voronkov, A. S. Golubev,
N. A. Konovalov, V. A. Krukov, and
E. P. Sychugova
Keldysh Institute of Applied Mathematics, Russian Academy of Sciences,
Miusskaya Sq. 4, Moscow, 125047, Russia
(095) 972-3646
Main approaches for elaborating portable parallel codes are considered. The REACTOR-P parallel program system is described. Traditional ways for creating portable parallel codes are examined. Main shortcomings of the message passing approach are discussed. A new data parallel language named C-DVM for implementing portable codes on multiprocessor computers has been developed. Some parallel numerical algorithms for 3D neutron diffusion problems are suggested. Results of numerical experiments have confirmed high efficiency of these algorithms and this new parallel language.
Table of contents
2. Portability of the SEQUENTIAL program system
3. Using traditional approaches TO elaborate parallel codes
4. Development of Methods and Tools for Creating Portable and Efficient Parallel Programs
Since 1985 we have been developing all neutron-physical codes within the framework of the unified package of application programs REACTOR1, which has been used in the Keldysh Institute of Applied Mathematics (KIAM) and other organizations for some years. The REACTOR package allows to carry out numerical calculation of stationary, quasistationary (calculation of burnup) and non-stationary (kinetic problems) processes in nuclear reactors in one-, two-, and three dimensional geometries. To solve the transport equation there can be used Diffusion, P1-approximation or the Method of Discrete Ordinates.
Up to now the REACTOR package has been used only on serial computers that narrowed areas of application. When new parallel systems became available the problem arose to create appropriate software effectively using the potentiality of parallel systems. Primarily it is necessary to elaborate software for modeling dynamic processes in nuclear reactors and especially to simulate emergency situations. These problems require a considerable increase in solution precision. High accuracy could be a compensation for practically a complete absence of full scale emergency experiments. Deep parallelization allows to use more precise and efficient solution methods. At present the REACTOR system is enhanced with new parallel computational modules. This new version of the package (Reactor-P) is intended to solve the most sophisticated problems requiring high performance and enlarged memory size. REACTOR-P runs on the distributed-memory multicomputer MBC-1002 based on i860-XP processors.
The package REACTOR-P is split into big separate codes (or sections according to this package terminology). Each section performs a considerable logically closed body of job, for example imputing reactor geometry or zone composition, computing equation coefficients and so on. Their interaction is performed through the archive (specialized data base) that resides into external storage. As a rule each section runs in the following manner: interacts with the program environment, inputs initial information from the data file, reads information from the archive, processes inputted information and writes results back to the archive. On this approach one can isolate those parts of the package (in the form of executable module) that being small as source code consume the major portion of the total CPU time. It is precisely these parts of the package that can be effectively parallelized.
To create portable software one must first of all use standard programming languages. A major portion of our reactor codes is written in Fortran-77. Additional potentialities that are absent in Fortran can be provided by means of the C language. At the present moment it is decided to use only ANSI C and Fortran. The joint use of Fortran and C poses a problem of language mixing. Theoretically there are two ways:
It is decided to use only the weak interface where possible.
To exclude code dependence on specific parameters and computer platform limitations a concept of parameter independence has been developed. Basic requirements are as follows:
To solve sophisticated scientific problems on distributed memory multicomputers we use the well-known approach based on describing the algorithm as a set of sequential processes interacting through the message passing. Under this approach two basic methods can be used to implement parallel algorithms. One of them is to use new parallel languages that are standard languages extended with new language constructions. The other method uses special libraries extending standard languages (for example Fortran or C) with the message passing means.
The Message Passing Interface library (MPI3) is an essential step in standardization of development tools. Being implemented on different hardware platforms this library principally gives a potentiality to write portable parallel codes. Comparatively low level of these library tools close to hardware structure of distributed memory systems allows to write effective parallel codes for such systems.
At present an MPI subset is implemented in KIAM using the program system Router4. Its functions are available by explicitly calling library routines. In addition, the message-passing language Fortran-GNS5 is implemented on MBC-100 in KIAM. This language is an extension of Fortran-77 in accordance to C. A. Thole’s suggestions6. These suggestions are based on the concept of the Abstract GENESIS Machine. In line with this concept the user’s task is represented as a set of sub-tasks which can be dynamically started on given processors of the distributed system. They interact with each other through message passing in one of three modes: synchronous, asynchronous, and no-wait. At present the concept of GENESIS computer is implemented as the Lib-GNS library elaborated to model basic features and statements of the Fortran-GNS. Codes written in Fortran-GNS may be ported onto any platform, that has a Fortran-77 compiler and Lib-GNS.
Some results about efficiency of these approaches shown by the package REACTOR-P are presented for a benchmark problem based on experiments performed at the United Kingdom ZEBRA facility7. This benchmark problem is a system of diffusion equations consisting of 26 energy groups. The finite-difference grid contains 16 planes each having 1519 points to give totally 24304 unknowns in every energy group. As it was mentioned above a parallel code is a set of interacting processes each running on a separate processor with local memory. On the other hand every section of the package (including a CPU-intensive section) must have access to the archive in the external storage. A problem arises how to organize simultaneous access of different processes to one archive under the necessary condition to keep information consistency. A number of alternatives have been analyzed to choose the most simple and logically clear scheme: one process is assigned to be the master, the others are slaves. Only the master process may interact with the “outer world”: (input/output from/to the archive, displaying messages on the monitor, receiving information from the keyboard and so on). Besides the master process organizes coherent running of slave processes: sends out initial information, gives permission to start/continue, gathers information on the achieved local accuracy in separate processes, decides on finishing the job, and at last performs necessary actions to complete running.
Calculations have been carried out in the multigroup neutron diffusion approximation in three-dimensional X-Y-Z geometry. This test problem is solved by using Fortran-77 together with MPI, implemented in the system Router. Solution parallelization of the diffusion equations is implemented by means of decomposition of numerical domain into layers along the vertical axis. Each layer consists of a number of grid planes and is processed by one processor. The information interaction involves exchange of values of neutron fluxes at the boundaries of layers.
According to our results the most effective splitting is to break down the whole grid into computational sub-areas with equal numbers of grid planes so that each sub-area corresponds to one processor. At the inner iterations all the processors start working simultaneously. The planes in each sub-area are ordered from the periphery to the center of reactor.
When solving the equation in each energy group the least parallelizable part is a fragment of code controlling inner iterative convergence. This algorithm runs on the processor that receives information on local convergence, analyses it, and decides whether to continue inner iterations or not. There are two possibilities to organize these processes on a set of processors. In the first case one of the local processors acts as the host processor. Performance results in this case are presented in Table 1
Table 1
Master and slave processes placed on single processor
N |
1 |
2 |
4 |
8 |
16 |
E |
100% |
97.41% |
96.75% |
85.87% |
49.89% |
In this Table E is the parallelization efficiency:
where![]() stands for
the time shown by the single processor code and
stands for
the time shown by the single processor code and ![]() is the time reported by
the N processor code.
is the time reported by
the N processor code.
Analysis has shown that the main cause decreasing the parallelization efficiency is a fragment of code searching the overall convergence of inner iterations. The fact is that the time spent on receiving the global criterion from the host processor increases considerably faster than linear function when the total number of processors grows. Because of this another parallelization method has been considered when a separate processor acts as the host. The basic idea is to superpose inner iterations and convergence analysis of the previous iteration. This admits one extra inner iteration in every group. This approach does decrease parallelization efficiency in case of few processors. But this approach is promising in case of massively parallel systems.
The following are the results obtained in case of 3, 5, 9, and 17 processors.
Table 2
Master and slave processes placed on different processors
N |
3 |
5 |
9 |
17 |
E |
60.32% |
78.10% |
80.28% |
59.73% |
Comparative analysis shows that in case of 17 and more processor code parallelization efficiency is greater than in the preceding case. Nevertheless the parallel efficiency drops as earlier when the number of processors grows.
The experience of development of the REACTOR-P system in Fortran-77 language with MPI library confirms the well-known opinion: the message passing approach has essential shortcomings.
First, the level of language facilities supporting program parallelism is too low. The lack of the global address and name space requires serious efforts for writing parallel programs. The debugging of message passing programs is still an open problem and a serious disadvantage for industrial development of parallel codes. The parallel program development needs using or creating the appropriate computational methods. To achieve the required performance it is necessary to modify or even to rewrite parallel programs many times. And this modification is much more complicated for the message passing programs than it is for sequential ones.
Second, the efficient program execution on massively parallel computers requires load balancing which is extremely difficult to provide in the message passing model. Workstation networks have become the most common parallel architectures available, but porting message-passing programs onto heterogeneous computer networks is a very difficult problem. It is necessary to develop new methods and tools for creating portable and efficient parallel programs for distributed memory computers.
The majority of experts believe that using data parallel languages (Fortran D8, Pandore C9, Vienna Fortran10, HPF11) is the most promising approach. These languages are versions of standard Fortran or C languages enhanced with data decomposition. The languages relieve the programmer from the burden of program partitioning and communication generation whenever a processor needs data from other processors. Based on the user-specified partitioning of data, the compilers must generate the corresponding parallel program for distributed-memory computers. It is unknown today whether they will be able to achieve performance comparable to message passing languages.
Research on data parallel languages, which was started in KIAM in 1993, allows us to arrive at the conclusion: the main weakness of data parallel languages is not only complexity of compilers, but also absence of explicit and clear model of parallel execution. This makes impossible to provide the user with convenient tools for analyzing execution and improving performance of his program.
A new model of parallel program execution was proposed in 199412. This model (DVM-model) combines the major advantages of PCF Fortran13 and HPF models and allows one to express functional and data parallelism in scientific and engineering applications on massively parallel computers.
The DVM name originates from two main notions - Distributed Virtual Memory and Distributed Virtual Machine. The former reflects the global address space, and the latter reflects the use of an intermediate abstract machine for the two-step mapping of the parallel program onto a real parallel computer. This distributed virtual machine consists of one or several multidimensional arrays of virtual processors, and defines the parallelism of the program. The programmer creates a suitable virtual machine for his program, then specifies the mapping of the program and data onto his virtual machine, and describes the rules of mapping this virtual machine onto the real parallel computer. This mapping is performed during run-time and does not require to recompile the source code.
The C-DVM language was developed on the basis of the DVM-model. The main principle of language development is: the programmer must have a possibility to specify exactly parallel execution of his program, but the intelligent compiler does not require the user to do it.
In fact, this principle determines directions of the language progress: from the complicated languages to simpler ones, from simple compilers to more complex ones. The direction of HPF development is different: from automatic parallelization to HPF1, then - to HPF2. The main effect of the difference in approaches is that at the cost of certain additional efforts the user of C-DVM is always able to make his program as efficient as it could be when conventional means for parallelization and message passing is used. Yet this does not involve any decrease in portability.
The C-DVM language has been developed concurrently and jointly with the REACTOR-P system. As a result, the DVM-model was improved considerably. Two experimental versions of the compiler were implemented and the language specification was revised twice. As a result, the C-DVM programming system was created. A short description of this programming system is presented below.
The system is based on the new language model and new methodology, it is aimed at simplifying development, debugging, testing, performance evaluation and maintenance of portable and efficient parallel programs.
The C-DVM language was developed via enhancing the C language in correspondence with the DVM-model. The parallel program is a code in the standard C language, in which the DVM directives specifying parallel execution of the program are inserted. The directives are transparent for standard C compilers, therefore DVM programs can be executed on workstations as usual sequential programs.
The language includes the following main features for parallelism description:
The compiler translates the parallel C-DVM code into a sequential C code including Lib-DVM library calls. The Lib-DVM is written in the C language and it uses the features of MPI or PVM14 for providing interprocessor communications. Therefore C-DVM can be used on any platform that has a C compiler and MPI or PVM installation.
For debugging a DVM program the following approach has been suggested. In the first stage, the program is debugged on a workstation as a sequential program using appropriate debugging methods and tools. In the second stage, a special execution mode for checking the DVM directives is used on the same workstation too. In the third stage, the program may be executed on a parallel computer (or on a workstation, simulating the MPI or PVM parallel machines) in a special mode, when intermediate results of its execution are compared with reference results (for example, the results of sequential execution). This mode is used for program testing as well.
There are tools for analyzing statistic data about program execution on a parallel computer (obtained in time of real execution or simulation). The DVM-program performance browser shows information about execution time of the DVM program and its fragments on every processor. Besides, the browser shows integral characteristics of the DVM-program and its fragments performance, for example, the parallelization efficiency.
Research and experimental programming of the REACTOR-P system in the C-DVM language have shown the following peculiarities of the main REACTOR-P code:
As a result, the following features for overlapping calculation and communication were included in the language:
The above mentioned computational code for solving multigroup diffusion neutron problems in 3D X-Y-Z geometry have been rewritten in the C-DVM language. The following modifications in codes have been made to increase parallelization efficiency:
Table 3 presents performance results shown by a code written in C-DVM for the same test problem. In this test problem there were 16*31*61 grid points in Z, Y, and X directions correspondingly. Grid points were distributed over processors either in Z-direction (denoted in the table, for example, by 8*1) or in Z- and Y-directions (denoted by 8*4 meaning 32 processor grid of 8 rows and 4 columns in Z and Y directions correspondingly, arrays were divided into 8 equal portions over Z-axis and approximately into 4 equal portions over Y-axis).
Table 3
Parallel efficiency of C-DVM code
N |
1 |
2*1 |
4*1 |
8*1 |
2*8 |
2*16 |
|
693.8 |
353.5 |
183.0 |
99.0 |
54.3 |
29.9 |
topt |
693.8 |
346.9 |
173.5 |
86.7 |
43.4 |
21.7 |
twst |
0.0 |
6.6 |
9.5 |
12.3 |
10.9 |
8.2 |
E |
100% |
98% |
95% |
88% |
80% |
73% |
where topt = ![]() / N, twst
=
/ N, twst
= ![]() - topt
- topt
As one can see from Table 3 the C-DVM program has high performance for distributed systems containing tens of nodes.
Table 4
Parallel efficiency of C-DVM code on 32 processor configuration
(as function of processor topology)
N |
16*2 |
1*32 |
8*4 |
4*8 |
2*16 |
|
36.4 |
33.6 |
30.8 |
30.8 |
29.9 |
topt |
21.7 |
21.7 |
21.7 |
21.7 |
21.7 |
twst |
14.7 |
11.9 |
9.1 |
9.1 |
8.2 |
E |
60% |
65% |
70% |
70% |
73% |
The indicated above results were obtained on the basis of statistical information produced by the special C-DVM performance browser.
The following Table 5 displays an example of statistics on C-DVM program performance, where:
Components of waste time:
Table 5
| N=1 | N=2(2*1) | N=4(4*1) | N=8(8*1) | N=16(2*8) | N=32(2*16) | |
| Tpar | 693.8 | 353.5 | 183.0 | 99.0 | 54.3 | 29.9 |
| Test | 693.7 | 689.0 | 670.4 | 658.8 | 633.3 | 635.6 |
| Eest | 1.0 | 0.97 | 0.92 | 0.83 | 0.73 | 0.66 |
| Twst | 0.0 | 18.0 | 61.0 | 133.2 | 236.0 | 320.9 |
| Tred | 0.0 | 0.12(0.0) | 9.8(9.0) | 20.4(16.7) | 120.5(111.0) | 157.9(130.0) |
| Tshd | 0.0 | 17.3(3.0) | 49.9(27.4) | 109.0(28.6) | 105.8(69.7) | 142.2(71.6) |
| Toth | 0.0 | 0.2 | 1.35 | 3.9 | 9.7 | 20.7 |
The experience on elaborating the portable program system REACTOR-P on parallel computer confirmed the correctness of the proposed approaches for implementing parallel codes. It has been shown that the elaborated parallel methods and approaches for their implementation give good results for distributed memory systems containing tens of processor nodes.
The experience on developing REACTOR-P programs in the C-DVM language allows us to state that the C-DVM programming system makes it much easier to develop programs on distributed memory computers.
It is very important that the C-DVM program can be dynamically (without recompilation) customized to application parameters (the number and size of arrays) and parallel computer configuration. This allows us to reduce the number of different versions of the program and to simplify program maintenance.
Further development of the REACTOR-P program system will be oriented to parallelization of neutron dynamic processes with thermohydraulic feedback and to modeling the problem of deep penetration radiation by using the transport equation in 3D geometry. To support it the C-DVM language will be extended with features for expressing functional parallelism.
Performance analysis of the REACTOR-P program written in the C-DVM language has shown that it is necessary to include into the language features for irregular mapping of arrays and computation (in a similar manner as in Vienna Fortran or HPF2 languages).
#define DVM(directive) /* This macros is blank for standard C compiler
and used by C-DVM compiler */
#define DO(v,l,u,s) for(v=l;v<=u;v+=s)
/*Definition of loops that can be made parallel in C-DVM */ #define N 1000 #define ITMAX 20
void main(void)
{
DVM(DISTRIBUTE [BLOCK] [BLOCK]) /* Pointers to arrays A and B
with block distribution */
float (*A)[N], (*B)[N];
int i,j,k; float eps,MAXEPS=0.5E-7;
A = malloc(N*N*sizeof(float)); // memory allocation for arrays A B = malloc(N*N*sizeof(float)); // and B they are used below
/* main iterative loop */
for(it=0;it<ITMAX;it++)
{ eps=0.0;
DVM(PARALLEL ON A[i][j]; REDUCTION MAX(eps))
/* Nest of two loops and description of reduction operation */
DO(i,1,N-2,1)
DO(j,1,N-2,1)
{
eps=max(abs(B[i][j] - A[i][j]),eps);
A[i][j] = B[i][j];
}
DVM(PARALLEL ON B[i][j]; SHADOW_RENEW A)
/*Copying shadow elements of array A from neighbouring
processors before loop execution */
DO(i,1,N-2,1)
DO(j,1,N-2,1)
B[i][j] = (A[i-1][j]+A[i+1][j]+A[i][j-1]+A[i][j+1])/4;
printf("it = %4d eps = %12.3e\n",it,eps);
if(eps < MAXEPS) break;
}
}
This research was performed under the financial support of ISTC Projects # 067-94 and # 068-94.